Deploying software to Heroku, Vercel, Netlify, or other cloud platform services is “easy.” Or, if it’s not easy, it’s a lot easier than building your own datacenter or managing your own fleet of bare metal, right? DevOps effort increases dramatically when you take away the aaSes:
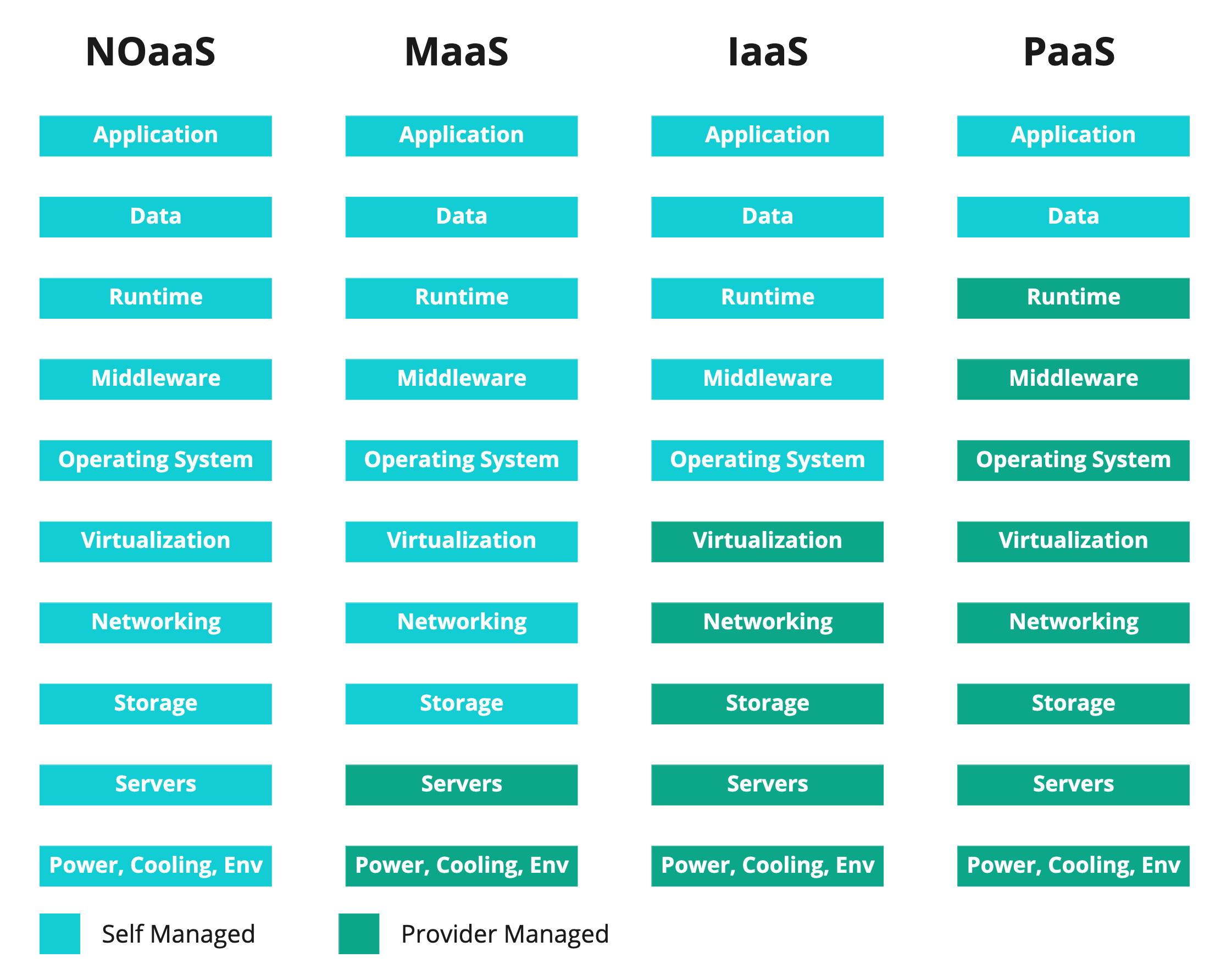
The number of components you become responsible for increases quite a bit with a move from Platform as a Service (PaaS), to Infrastructure as a Service (IaaS), to Metal as a Service (MaaS), to wholly self-managed, on-premises workloads. So why would anyone do this? Clearly more to manage == more costs, less time, and greater complexity. What strategic advantage do we gain by building, managing, and refreshing our own infrastructure?
Well, it turns out there are several really good reasons for running your own metal. Here are a few:
- Your workloads are pretty steady. i.e. not a ton of peak and trough, but steady utilization, or steady growth.
- Your software must be really close to your users. Like 1ms close. And you’re going to deploy a fleet of hardware close to your users (think vision processing for airport security screening).
- You need specialized hardware for acceleration, like a GPU, TPU, ASIC, FPGA, etc. If you’re doing any exotic mathematics, this may be the reason you clear the clouds.
- You have a business contract that says you must maintain your own private infrastructure. DoD and other Government contracts may require this, for example.
- Just because.
That last one is a real thing now. A lot of people seem to be interested in ditching big tech. Or, at least being less dependant upon big tech. I’ve been hearing a lot about hybrid-cloud, multi-cloud, no-cloud, and serverless on servers lately (after all, behind every serverless architecture is, well, a bunch of servers). It’s not as baseless as it sounds, either. Metal as a Service (something like Equinix Metal) should be given serious consideration over the other service offerings, especially if you jive with any of the reasons above and are willing to invest engineering time managing your OS, orchestration, monitoring, and deployment layers. Why?
- Deployment tooling is getting better.
- It’s a cheaper, happy medium.
- It’s still declarative and scalable.
- You will experience much better performance.
Orchestrators are becoming more mature and deploying on bare metal infrastructure is more attainable than ever before. I especially love the Hashicorp Nomad project, which embraces the Unix philosophy of “do one thing well” and really is “orchestration made easy.” Creating PaaS-like experiences for developers and engineers is a lot easier now as well. Hashicorp Waypoint is a great abstraction tool for deploying on nomad or Kubernetes, for example. Swarm mode, built into Docker is another great option for getting up and running quickly.
By the way, I write one of these every few weeks or so. Sign-up with your email here to receive the latest, as soon as it’s posted!
What do we gain?
Money and Freedom. The infrastructure is yours, do whatever you want with it. If you need to scale you can add more nodes. If you’re running container workloads or other server-side processing that is intensive, the MaaS model also makes good financial sense.
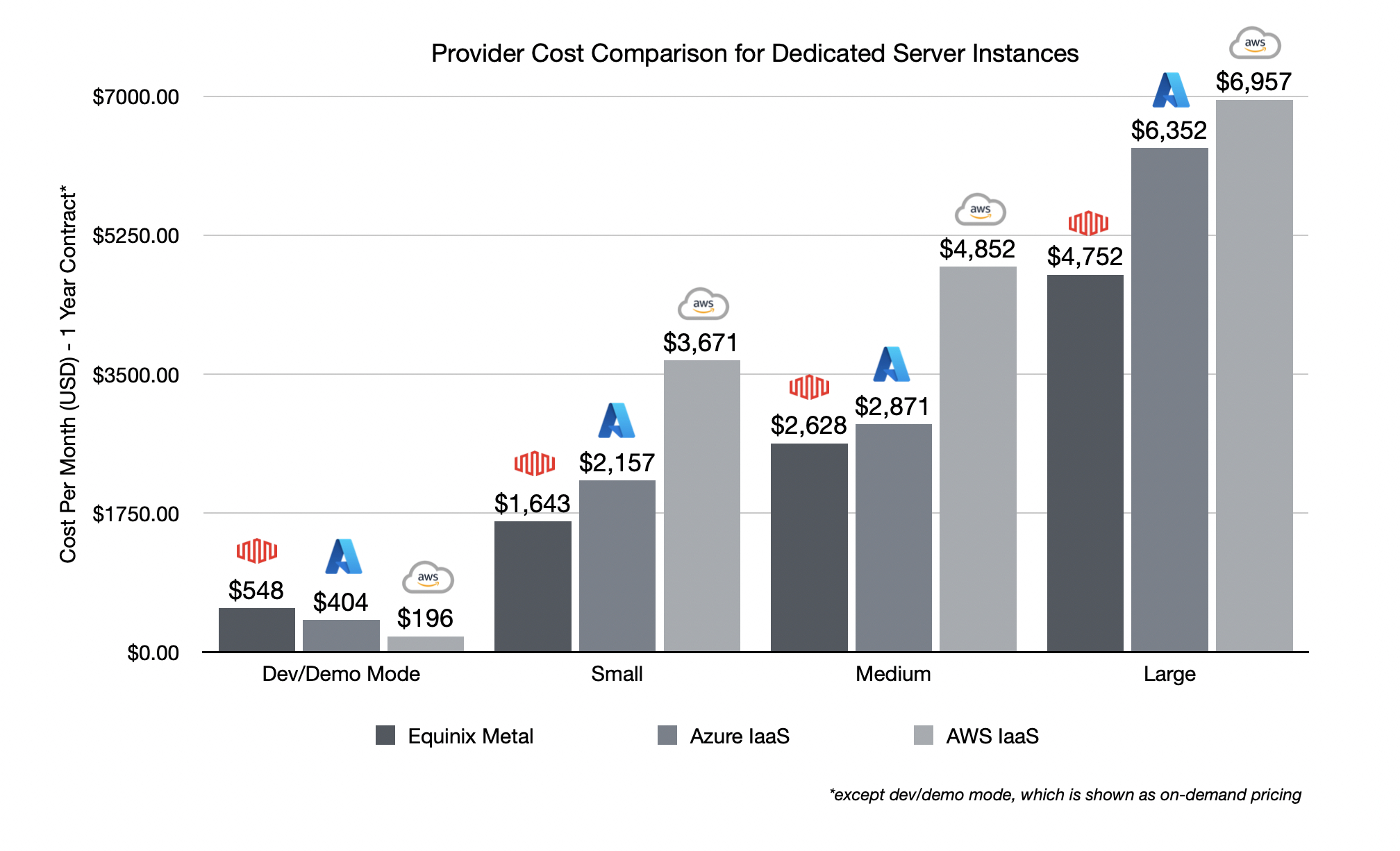
This example shows the costs of a t-shirt-sized, 3-node Nomad cluster compared using equinix metal, Azure VMs, and AWS Dedicated instances, with identical storage options for each. It’s cheaper to get fully dedicated bare metal servers from someone like Equinix metal than it is to provision virtual machines on the cloud providers. You’re also not really taking on any additional responsibility. If you were running VMs for your workload on Azure, running bare metal instances is likely the same thing, but, better. If you were using a managed Kubernetes service (your just paying for VPS running k8s), you do take on the responsibility of managing the orchestrator. To which I say, use a simpler orchestrator. Bootstrapping and managing your own clusters using GitOps and CI/CD pipelines is a very reliable approach.
Having a constantly-provisioned set of infrastructure via virtual machines, managed Kubernetes services, or other platform services is great, but you will gain significant performance improvements using bare metal. When you’re scheduling right on the CPU and memory resources rather than shared or dedicated virtual instances several layers removed, you actually get what you pay for, and for less. Using bare metal, your users will spend less time in queues on the cloud waiting for shared resources.
How do we do it?
A stack could look something like this, via a GitLab pipeline:
- Use Terraform to procure bare metal servers from Equinix metal.
- Use the custom data provider to join the machines you create as runners in your Gitlab project.
- Use an ansible playbook to bootstrap your nodes with nomad, integrating with Gitlab for developer access via OIDC.
- Consume your newly created infrastructure in your CI/CD pipeline using waypoint or terraform/nomad CLI.
Add Prometheus monitoring and alerting, security scanning with Trivy, and you’re good to go! Maybe we don’t need so many aaSes after all. What do you think?
If you need help with DevOps and software delivery, reach out.