I found myself recently in need of a simple and reliable way to schedule container services across a menagerie of servers; some with GPUs and some not, for AI inferencing. The goal was to match containers which require a GPU with hosts that can provide one. I like docker swarm mode for it’s no-frills user experience, and decided to use it for this project. It turns out docker swarm provides a straightforward method for addressing GPU hardware. This solution makes use of a feature within docker swarm called resource reservations.
This feature provides for scheduling decisions based on inferencing hardware. For example, you can specify a quantity of GPUs your service requires, and swarm will schedule it only on the nodes which house at least that many GPUs. Swarm is also aware of previously scheduled services when considering new service placement. If there is a service resourced to a GPU, swarm will not place additional services on that node unless there are an adequete number of additional GPUs available for consumption. Pretty neat, huh? Let’s set it up!
By the way, I write one of these every few weeks or so. Sign-up with your email here to receive the latest, as soon as it’s posted!
Some considerations. 🤔
- The CUDA version you install on the target host(s) generally must match the CUDA version your project requires. You will likely be able to complete builds of your code with mismatching CUDA versions, perhaps even training, but inferencing seems to fail when the underlying CUDA runtime version does not match what’s in your container. For Ubuntu server systems, the Ubuntu apt repositories include NVIDIA drivers. Below are the corresponding CUDA versions for each driver version.
- In a multi-node orchestration/scheduling system you must account for workload placement. This can be accomplished through orchestrator-specific placement constraints for resource types or by manual methods. This guide covers resource constraints with docker swarm mode.
- You may wish to handle concurrent inferencing jobs across several nodes in a cluster. In scenarios such as these, you must solve for container placement constraints and GPU interface-level constraints. Generally, you must address the hardware via concurrent means in your APIs/inferencing services (using
torch.multiprocessing, for example).
Ubuntu Server Driver and CUDA Versions
| NVIDIA Driver Version | CUDA Version |
|---|---|
nvidia-driver-525-server | CUDA 12.0 |
nvidia-driver-515-server | CUDA 11.7 |
nvidia-driver-450-server | CUDA 11.0 |
Configuring docker for AI inference. 🛠️
Start by installing the NVIDIA drivers/utils on your host(s):
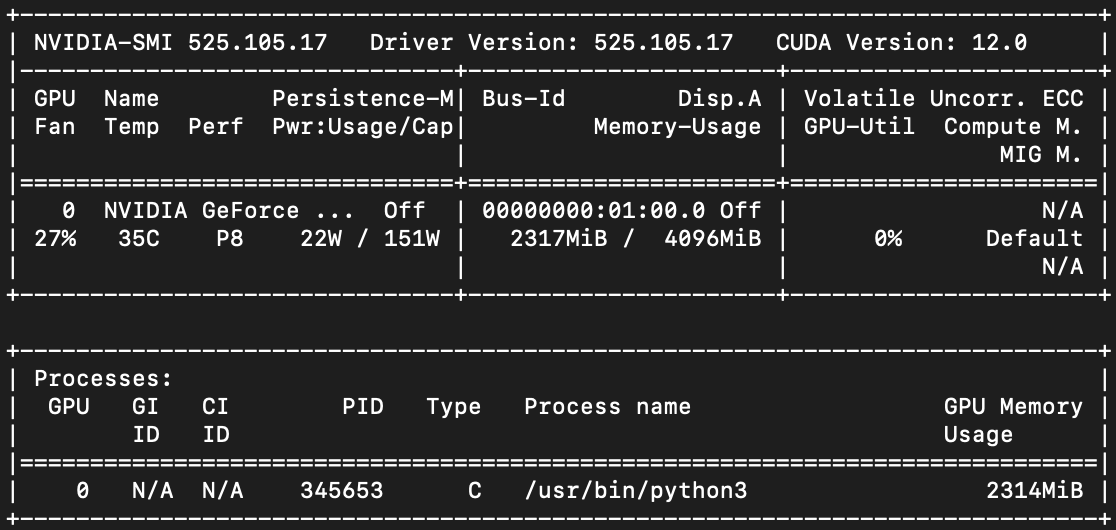
apt install -y nvidia-driver-525-server nvidia-utils-525-serverReboot and verify your GPU is present and active. You should see something like this:
nvidia-smi
- Install the Nvidia container toolkit, which makes it possible for docker to passthrough the GPU(s). You can run this bash script to install. It will also perform the next few steps, like setting the default container runtime to nvidia, and finding and loading the GPU UUIDs as
node-generic-resourcesin the/etc/docker/daemon.jsonfile. This is how docker swarm orchestrates containers with GPU placement constraints. The script does several things:
- Installs the Nvidia container toolkit for your version of ubuntu server.
- Configures the Nvidia Container Toolkit runtime as “docker.”
- Performs the following updates to docker’s
daemon.jsonif not already set:- Sets the
default-runtimetonvidia. - Adds the
node-generic-resourcesarray. - Runs
nvidia-smito get all GPU UUIDs for the system and adds them to thenode-generic-resourcesarray.
- Sets the
- Restarts the docker daemon to apply the changes.
Validating and deploying. 🚀
Once you’ve setup the prerequisites, you can run something like the following to test your docker configuration. You should get a similar response as running nvidia-smi on the host:
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:12.0.0-base-ubuntu20.04 nvidia-smi
Finally, create a swarm.yml file (or use your existing docker-compose.yml) for your services and add the following section to enable the GPU placement constraint. This solution is a little quirk in docker swarm I stumbled upon here:
version: "3.8"
services:
example:
image: nvidia/cuda
deploy:
# Add this to schedule this service on nodes with GPUs
resources:
reservations:
generic_resources:
- discrete_resource_spec:
kind: "NVIDIA-GPU"
value: 1
The value here denotes how many GPUs the service requires. If you have several GPUs installed in a system and enter 4 for this value, docker swarm mode will schedule your services on nodes that have 4 GPUs.
Example with OpenAI’s Whisper. 🎙️
I stitched together a little demo project that uses this pattern to provide an inferencing API for OpenAI's Whisper. It’s a simple flask API that accepts an audio file, and returns the text transcription. You can deploy it to a machine with Nvidia GPUs by cloning the project and running docker compose up -d from the root of the repository. Provided you have followed all of the steps up to this point, docker will build an image based on nvidia/cuda, add the src folder which contains the flask app, install dependencies, and start the container. When the container starts, it will output the device type it will use for inferencing (either cpu or cuda) and load the model:
root@gargantua:/repos/metal-whisperer# docker logs containername
[2023-05-30 18:36:11 +0000] [1] [INFO] Starting gunicorn 20.1.0
[2023-05-30 18:36:11 +0000] [1] [INFO] Listening at: http://0.0.0.0:8080 (1)
[2023-05-30 18:36:11 +0000] [1] [INFO] Using worker: sync
[2023-05-30 18:36:11 +0000] [7] [INFO] Booting worker with pid: 7
cuda
100%|███████████████████████████████████████| 461M/461M [00:10<00:00, 45.3MiB/s]
Once your container has started, you can record an audio file, and submit it for transcription and receive a transcription. Here’s an audio clip from the movie Oblivion and the resulting transcription using the “small” model.
christian@alpha-centauri ~ % curl -F files=@Downloads/oblivion.m4a http://192.168.4.141:8080
{"results":[{"filename":"files","transcript":" I can't help notice your respiration
and heart rate have increased. I'm just excited to finally meet you, silly. There's
been a pattern of insubordinate behavior recently. Yeah. I feel bad about that.
Voice analysis indicates you are lying to me, Jack. Tell me why you're here. You
have five seconds. I want you here to live. I want our species to survive. This is
the only way. Proceed to landing, atmosphere provided."}]}
Here’s the transcript from the “base” model:
christian@alpha-centauri ~ % curl -F files=@Downloads/oblivion.m4a http://192.168.4.141:8080
{"results":[{"filename":"files","transcript":" I can't help notice your respiration
and heart rate have increased. I'm just excited to finally meet you, Silly. There's
been a pattern of insubordinate behavior recently. Yeah. I feel bad about that.
Voice analysis indicates you are lying to me, Jack. Tell me why you are here. You
have five seconds. I want you here to live. I want our species to survive. This is
the only way. Proceed to landing, at this vehicle provided."}]}
This is running on an nvidia gtx 970 I have in an old PC. Using the “small” model inferencing takes 3.04 seconds and is a little more accurate, as you can see. Inferencing with the “base” model on my setup takes 1.59 seconds. Further optimizations could be made in the transmission of the audio data to make this faster.
If you’d like to build a similar app, I recommend using one of Nvidia’s base images to start with, because they include the CUDA runtime environment which torch and others require for GPU processing. Running the above project with a base of python/slim, for example, would result in CPU inferencing, rather than GPU with CUDA. Importantly, you may also require an active CUDA environment during build time, in which case you will need to do a couple of other things. For one, you’ll have to run your builds on a machine that has a GPU and pre-requisites installed, as highlighted earlier. Secondly, you’ll need to prefix your docker build commands with DOCKER_BUILDKIT=0 to make sure the nvidia runtime is utilized for the container build. You can organize both of these requirements as part of your gitlab, github, etc. pipelines as needed.
If you need help with product development and software delivery, reach out.